目次
はじめに
本稿ではTensorflowの公式チュートリアルに従い、Tensorflowの基礎を押さえていきます。
チュートリアル 公式https://www.tensorflow.org/tutorials
チュートリアル実施にあたり、以下の悩みを抱えている方に向けて丁寧な解説をしていこうと思います。
- チュートリアルの内容をもとにTensorflow, Kerasの基礎知識を一から学び、実践で使える知識を身に着けたい
- なんとなくチュートリアルを終えて動きはしたけど、結局何をやってるのかがイマイチわからない
- チュートリアルの説明より、もっと細かい解説が見たい
入門向けクイックスタート 概要
チュートリアルの「入門者向けクイックスタート」から始めます。
https://www.tensorflow.org/tutorials/quickstart/beginner?hl=ja
ここではKerasを使って以下のことを行います
- 画像を分類するニューラルネットワークを構築する。
- そのニューラルネットワークをトレーニングする。
- モデルの精度を評価する。
チュートリアルではGoogle Colaboratoryを活用していましたが、筆者はWSL上で構築した仮想OS上で実行します。
WSL上に環境構築する方法は以下を参照してください。
https://sidefire-engineer.com/node-red入門/
チュートリアルではMnistデータを用います。
MnistとはAIの分野でのHello Worldにあたる基本プログラムで使われる画像データセット。手書きの数字60,000枚とテスト画像10,000で構成されています。
各画像は28×28のピクセル、0~255の白黒のスケールで表されます。
ソースコード全体は以下となります。後ほど一つずつ細かく解説していきます。
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(optimizer='adam',
loss=loss_fn,
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test, verbose=2)ソース解説
ソースコードの細かい内容を解説していきます。
①tensorflowのインポート
tensorflowをインポートします。kerasはtensorflowに統合されているため、tensorflowをインポートするだけでkerasの各メソッドもtf.keras.xxxで呼び出せるようになります。
import tensorflow as tf②mnist向けデータセット取得
mnistのデータセットはtensorflowインストール後に使える状態となっているため、以下でmnistのデータセットを読み込みます。
mnist = tf.keras.datasets.mnist尚、kerasが保持するデータセットは以下に詳細な記載があります。
https://keras.io/ja/datasets/
③ mnistデータの読み込み
load_dataメソッドで以下のデータ群を各配列に格納。
- x_train:学習用の画像データ 28x28の白黒画像データ 60,000枚
- y_train: 学習用のラベルデータ ラベル(0-9の数値)60,000枚
- x_test:検証用の画像データ 28x28の白黒画像データ10,000枚
- y_test:検証用のラベルデータ ラベル(0-9の数値)10,000枚
(x_train, y_train), (x_test, y_test) = mnist.load_data()④ 学習モデルを構築する
ここからは学習モデルを構築します。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])tf.keras.models.Sequentialは層を重ねてモデル構築をするメソッドです。Sequentialのカッコ内で指定したレイヤーでモデル構築が出来ます。
各層の説明をしていきます。
- Flatten層:入力画像をチャネルに関係なく全て1次元配列に変換する
- Dense層:全結合層。その層内の全てのニューロンが次の層の全ニューロンと接続する
- Dropout層:過学習を防ぐためにレイヤーの出力をランダムに0に落とす
定義の説明だけだとイメージが沸かないと思うので、図を使って説明します。
ここで、チュートリアルで構築したモデルのレイヤー構成を確認するため、
pythonコードの最後に以下を追記し、mnist.h5というファイルを出力させます。
model.save('mnist.h5')また、レイヤー構成を確認するため、学習済みモデルのビジュアライズツールであるnetron使います。
netronは以下のサイトでブラウザ上で利用できます。
https://netron.app/
netronでmnist.h5を読み込んでみると以下の図となりました。
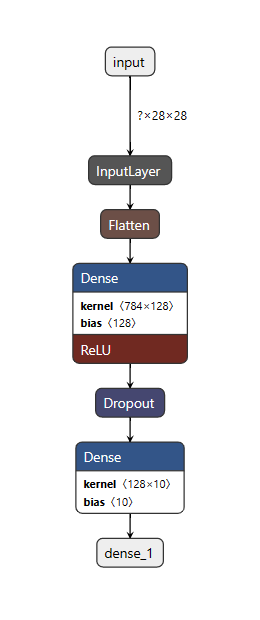
順を追って説明すると、Flatten層で1次元配列に変換されるため、1次元で出力784の層が出来上がります。
その後、Dense層では出力が128と指定されているため、1次元の出力128の層が出来、活性化関数Reluを通した値が出力されます。(Dense層の784x128の部分)
Relu関数は負の入力は0、0以上は正の入力をそのまま出力する関数です。
Dropout層でランダムにニューロンの接続を断ち切り、最後のDense層で0~9の10カテゴリの出力を出します。
(2つ目のDense層の128x10の部分)
⑤ モデルのコンパイル
学習のためのモデルの設定を行います。
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(optimizer='adam',
loss=loss_fn,
metrics=['accuracy'])損失関数、最適化については以下が分かりやすいので参考にしてください。
https://qiita.com/omiita/items/1735c1d048fe5f611f80
詳細は割愛しますが、最適化関数にはデファクトスタンダードで使われているAdamを設定しています。
損失関数は、機械学習モデルが算出した予測値と実際の正解価とのずれを算出する関数です。
以下を参考にすると、ラベルデータがone-hot表現(1つの成分が1、それ以外が0)の場合はCategoricalCrossentropyを用い、整数表現の場合はSparceCategoricalCrossentropyを用いるとのことです。今回はCategoricalCrossentropyを使っていますね。
https://yhayato1320.hatenablog.com/entry/2021/05/18/110152
metricsでは評価関数の指定が出来、ここでは正解率"accuracy"が使用されています。
モデルの設定には、実際は他にも様々な設定可能な項目はあります。
詳細は以下を参照ください。
https://keras.io/ja/models/model/
⑥ モデルのトレーニング
model.fitでモデルのトレーニングを行います。
epochsは学習の回数を指定できます。1回の学習
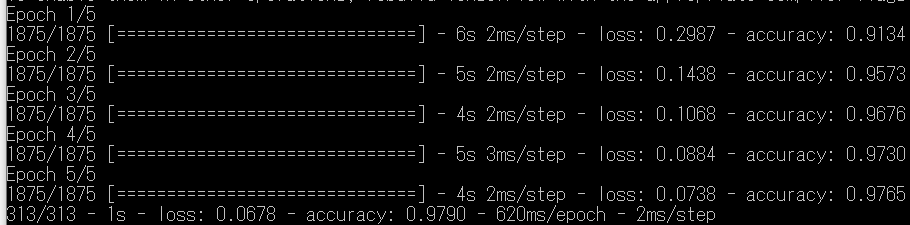
model.fit(x_train, y_train, epochs=5)学習は1回だと正解率が上がり切っていないため、5回の設定となっています。
結果より、accuracyがだんだん上がっていることが分かります。
⑦ モデルの評価
model.evaluateでモデルの評価を行います。
入力データ、ラベルデータに対する評価結果を返します。
verboseは0で標準出力のログ無し、1でプログレスバーで標準出力、2でエポックごとに1行のログを出力します。
model.evaluate(x_test, y_test, verbose=2)まとめ
この記事では、Tensorflowのチュートリアルを通して、Tensorflow/kerasの基礎について解説しました。
チュートリアルでは必要最低限の使い方までとなるため、今後はさらに深い使い方を見ていきたいと思います。





